
ML projects
1. Company-based Projects
a. Product delivery date prediction for an e-commerce company

I worked on a project with an e-commerce company where we focused on predicting product delivery dates. As per privacy agreements, I am unable to disclose the name of the company. The project aimed to improve customer experience by providing more accurate delivery estimates. We utilized a combination of historical data and machine learning algorithms to predict the estimated delivery date based on various factors such as shipping location, product availability, and past delivery performance. The resulting model showed significant improvements in prediction accuracy and helped the company enhance its overall customer service.
A sample code used for preprocessing is showed here
b. Time-series modeling & forecasting for a NY-based AdTech company

This project involved time-series analysis & forecast for the company’s core product called “Card-Linked Offer”. More specifically, the project involved aggregating data from multiple sources, cleaning & parsing, then building robust forecast models. One major question I sought to provide an answer to was: “Who will be the top 3 best-performing merchants for Q1 2024?”
A repository containing just the CLO forcast aspect of the project can be accessed here
c. Simple EDA for a diagnostic testing and development company
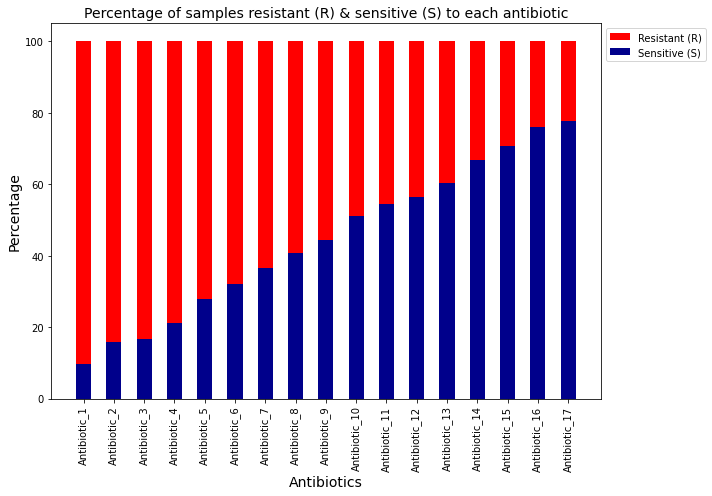
The objective of this project is to perform an exploratory data analysis (EDA) on different bio datasets e.g urine test samples. For the urine test dataset, some specific questions to be answered were: What were the amount of samples resistant/ sensitive to each antibiotic? ;The presence of each resistance gene accross the samples ;The distribution of cell counts for each organism.
Unit tests were also written to ensure the accuracy and integrity of data manipulations.
Sample codes can be accessed here
2. Computational chemistry
a. Latent-variable machine learning framework
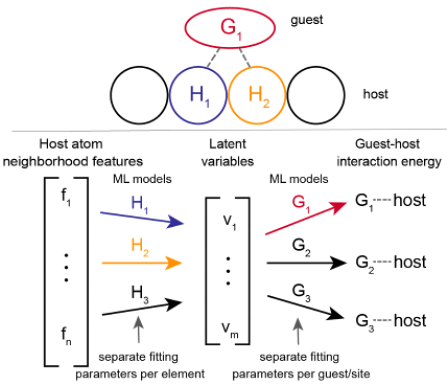
This project involved the creation of a novel machine learning framework that incorporates chemical principles and facilitates the development of general, interpretable, and reusable models. The framework leverages latent variables to construct a series of submodels, each of which tackles a relatively straightforward learning task. This approach enhances data-efficiency and encourages transfer learning. Moreover, the architecture is grounded in fundamental chemical principles, such as the concept of elements as distinct entities.
The publication for this work can be accessed here. An implementation of this framework for predicting bulk and surface adsorption energies is deployed here with the source code accessible in my group’s repository.
Models were deployed using streamlit.
b. Alloy screening with machine learning
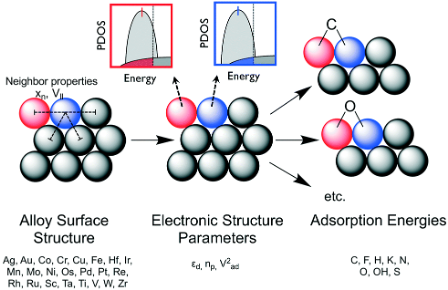
Here, an efficient, robust ML framework capable screening a vast number of alloys for their catalytic performance is created. This framework allows predictions without any quantum calculations. Further we applied our framework to screen more than 107 unique surface sites on approximately 106 unique surfaces for 7 important reactions. Furthermore, alloy surfaces with high predicted catalytic performance are identified.
The publication for this work can be accessed here. An implementation of this framework for predicting bulk and surface adsorption energies is deployed here with the source code accessible in my group’s repository.
Models were deployed using streamlit
c. Bayesian optimization for Single-atom alloy discoveries
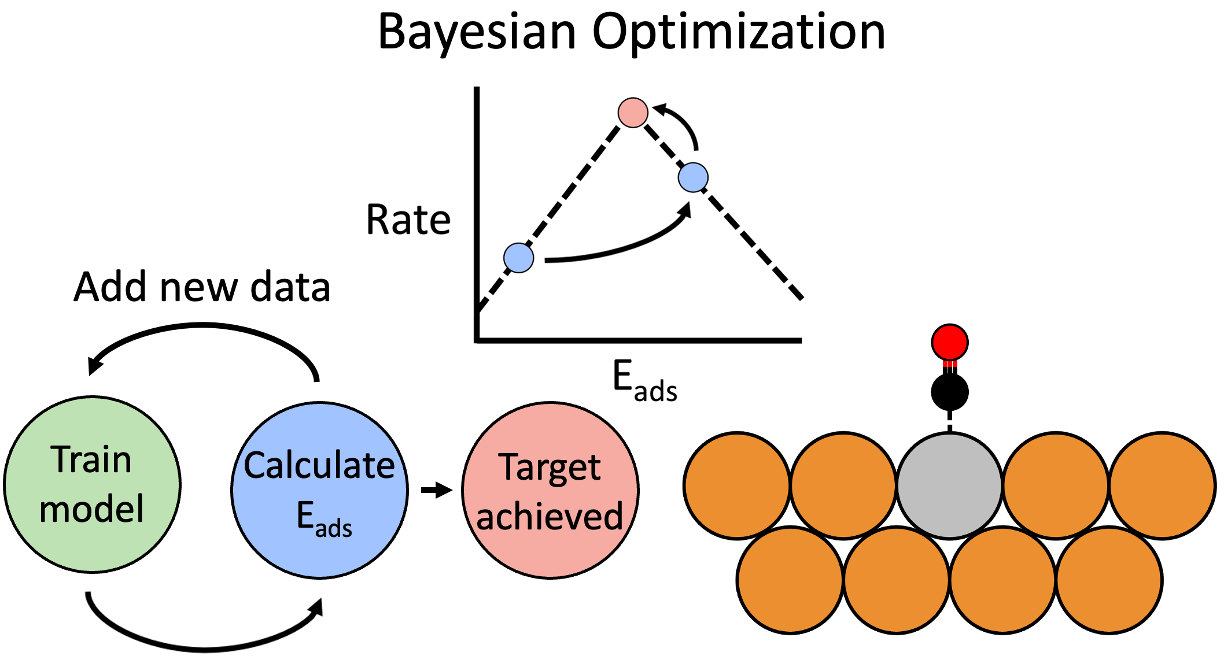
In this study, Bayesian optimization (BO) is employed in our quest for high-performance catalysts. Our results indicate that this BO process can be initiated with just a small dataset of 2 to 8 data-points and can often rapidly identify the optimal single-atom alloy surface within a few iterations. This approach was successfully implemented to efficiently explore multiple datasets and adsorption systems and outperformed a random search strategy. In practical applications, this BO process was used to identify optimal catalysts for both alkane transformations and CO2 reduction.
The publication for this work can be accessed here.
d. ML in understanding oxophilicity and carbophilicity in metals
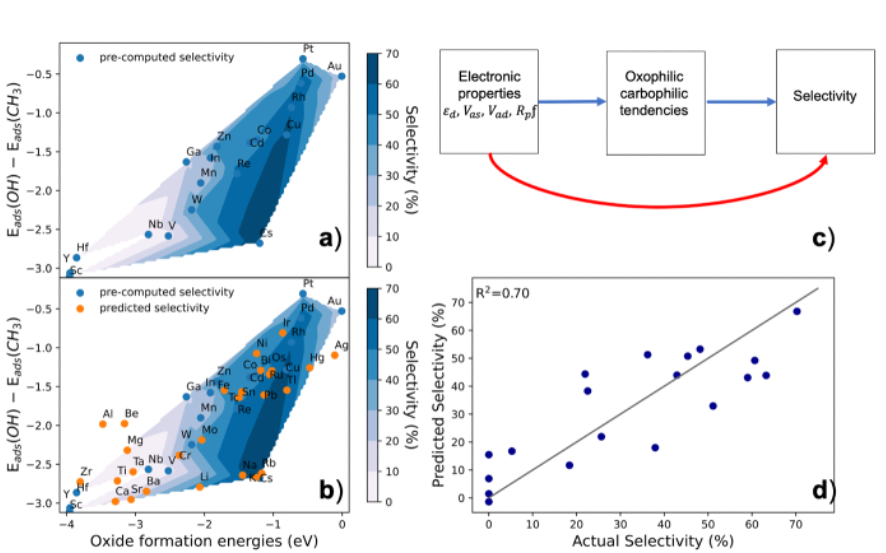
In this work, we elucidate the factors that control how oxophilic or carbophilic a metal is by creating a predictive model and applying it to a variety of data sets for transition metals and main group metals, including DFT-calculated adsorption energies and experimental formation energies. Our model is easily interpretable and accurately describes oxophilic and carbophilic trends across different regions of the periodic table. This model captures the ionic contribution to bonding, the adsorbate-sp contribution to bonding, and the adsorbate-d contribution to bonding by using the reduction potential, matrix coupling elements, band centers, and band filling. As a simple application, we demonstrate the utility of oxophilicity and carbophilicity in rapidly screening metal dopants for improved selectivity for ethylene epoxidation on silver-based catalysts.
The publication for this work can be accessed here.